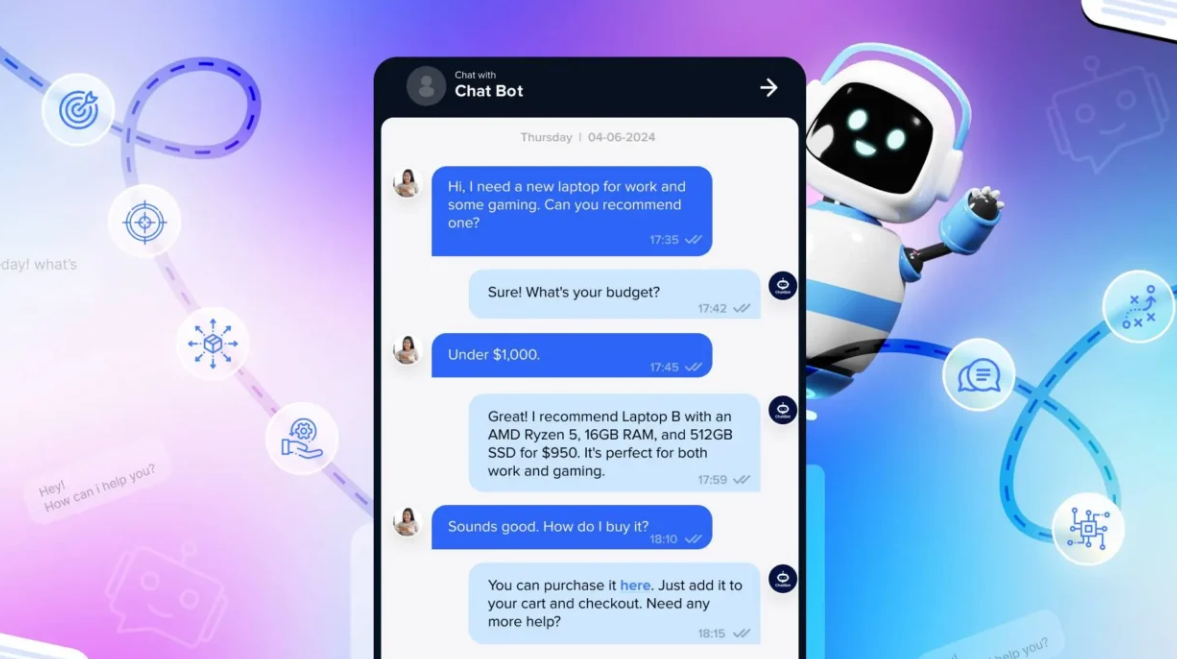
Testaa tekoälyä OMALLA verkkosivullasi 60 sekunnissa
Katso kuinka tekoälymme analysoi verkkosivusi välittömästi ja luo personoidun chatbotin - ilman rekisteröitymistä. Syötä vain URL-osoitteesi ja katso kuinka se toimii!
Valmis 60 sekunnissa
Ei vaadi koodausta
100% turvallinen
Nöyrä alku: Varhaiset sääntöpohjaiset järjestelmät
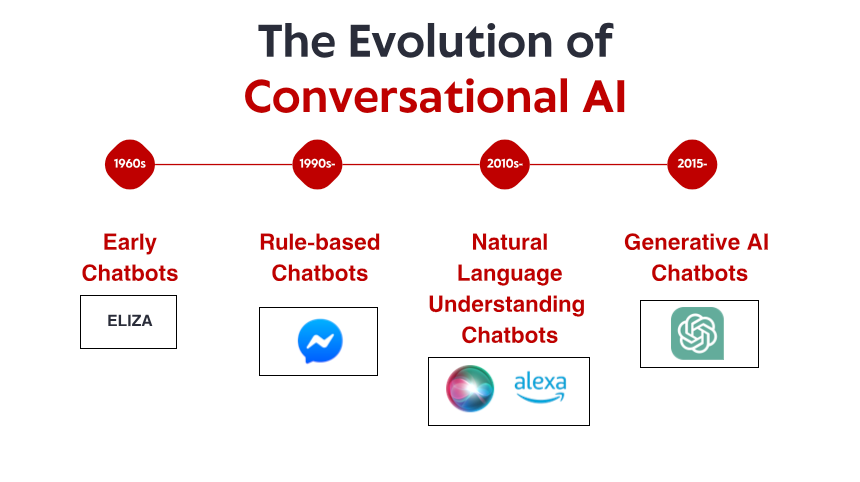
Keskustelevan tekoälyn tarina alkaa 1960-luvulla, kauan ennen kuin älypuhelimet ja puheavustajat tulivat kotitalouksien perustarpeisiin. Tietojenkäsittelytieteilijä Joseph Weizenbaum loi MIT:n pienessä laboratoriossa sen, mitä monet pitävät ensimmäisenä chatbotina: ELIZA. ELIZA, joka on suunniteltu simuloimaan rogerialaista psykoterapeuttia, työskenteli yksinkertaisten kuvioiden sovitus- ja korvaussäännöissä. Kun käyttäjä kirjoittaa "Olen surullinen", ELIZA saattaa vastata "Miksi olet surullinen?" – ymmärryksen illuusion luominen muotoilemalla väitteet uudelleen kysymyksiksi.
Se, mikä teki ELIZAsta merkittävän, ei ollut sen tekninen hienostuneisuus – tämän päivän standardien mukaan ohjelma oli uskomattoman yksinkertainen. Pikemminkin se oli sen syvällinen vaikutus käyttäjiin. Huolimatta siitä, että he tiesivät puhuvansa tietokoneohjelmalle ilman todellista ymmärrystä, monet ihmiset loivat emotionaalisia yhteyksiä ELIZAn kanssa jakaen syvästi henkilökohtaisia ajatuksia ja tunteita. Tämä ilmiö, jonka Weizenbaum itse piti huolestuttavana, paljasti jotain perustavanlaatuista ihmisen psykologiasta ja halukkuudestamme antropomorfoida jopa yksinkertaisimmat keskustelurajapinnat.
Koko 1970- ja 1980-lukujen ajan sääntöpohjaiset chatbotit seurasivat ELIZAn mallia asteittain parannuksilla. Ohjelmat, kuten PARRY (simuloivat vainoharhaista skitsofreenistä) ja RACTER (joka "kirjoitti" kirjan nimeltä "Poliisiparta on puoliksi rakennettu") pysyivät tiukasti sääntöpohjaisen paradigman sisällä – käyttämällä ennalta määritettyjä malleja, avainsanahakua ja mallivastauksia.
Näillä varhaisilla järjestelmillä oli vakavia rajoituksia. He eivät itse asiassa pystyneet ymmärtämään kieltä, oppimaan vuorovaikutuksesta tai sopeutumaan odottamattomiin tuloksiin. Heidän tietämyksensä rajoittuivat ohjelmoijat nimenomaan määrittelemiin sääntöihin. Kun käyttäjät väistämättä eksyivät näiden rajojen ulkopuolelle, älykkyyden illuusio murtui nopeasti ja paljasti alla olevan mekaanisen luonteen. Näistä rajoituksista huolimatta nämä uraauurtavat järjestelmät loivat perustan, jolle kaikki tulevaisuuden keskustelun tekoäly rakentuisi.
Se, mikä teki ELIZAsta merkittävän, ei ollut sen tekninen hienostuneisuus – tämän päivän standardien mukaan ohjelma oli uskomattoman yksinkertainen. Pikemminkin se oli sen syvällinen vaikutus käyttäjiin. Huolimatta siitä, että he tiesivät puhuvansa tietokoneohjelmalle ilman todellista ymmärrystä, monet ihmiset loivat emotionaalisia yhteyksiä ELIZAn kanssa jakaen syvästi henkilökohtaisia ajatuksia ja tunteita. Tämä ilmiö, jonka Weizenbaum itse piti huolestuttavana, paljasti jotain perustavanlaatuista ihmisen psykologiasta ja halukkuudestamme antropomorfoida jopa yksinkertaisimmat keskustelurajapinnat.
Koko 1970- ja 1980-lukujen ajan sääntöpohjaiset chatbotit seurasivat ELIZAn mallia asteittain parannuksilla. Ohjelmat, kuten PARRY (simuloivat vainoharhaista skitsofreenistä) ja RACTER (joka "kirjoitti" kirjan nimeltä "Poliisiparta on puoliksi rakennettu") pysyivät tiukasti sääntöpohjaisen paradigman sisällä – käyttämällä ennalta määritettyjä malleja, avainsanahakua ja mallivastauksia.
Näillä varhaisilla järjestelmillä oli vakavia rajoituksia. He eivät itse asiassa pystyneet ymmärtämään kieltä, oppimaan vuorovaikutuksesta tai sopeutumaan odottamattomiin tuloksiin. Heidän tietämyksensä rajoittuivat ohjelmoijat nimenomaan määrittelemiin sääntöihin. Kun käyttäjät väistämättä eksyivät näiden rajojen ulkopuolelle, älykkyyden illuusio murtui nopeasti ja paljasti alla olevan mekaanisen luonteen. Näistä rajoituksista huolimatta nämä uraauurtavat järjestelmät loivat perustan, jolle kaikki tulevaisuuden keskustelun tekoäly rakentuisi.
Tiedon vallankumous: Asiantuntijajärjestelmät ja strukturoitu tieto
1980-luvulla ja 1990-luvun alussa syntyivät asiantuntijajärjestelmät – tekoälyohjelmat, jotka on suunniteltu ratkaisemaan monimutkaisia ongelmia matkimalla ihmisten asiantuntijoiden päätöksentekokykyjä tietyillä aloilla. Vaikka näitä järjestelmiä ei olekaan suunniteltu ensisijaisesti keskustelua varten, nämä järjestelmät edustivat tärkeää evoluution askelta keskustelun tekoälyssä ottamalla käyttöön kehittyneemmän tiedon esityksen.
Asiantuntijajärjestelmät, kuten MYCIN (joka diagnosoi bakteeri-infektiot) ja DENDRAL (joka tunnisti kemiallisia yhdisteitä), järjestivät tietoa jäsenneltyihin tietokantoihin ja käyttivät päätelmäkoneita johtopäätösten tekemiseen. Kun tätä lähestymistapaa sovellettiin keskustelukäyttöliittymiin, chatbotit pystyivät siirtymään yksinkertaisen mallin täsmäyttämisen lisäksi kohti jotain, joka muistuttaa päättelyä – ainakin kapeilla aloilla.
Yritykset aloittivat käytännön sovellusten, kuten automatisoitujen asiakaspalvelujärjestelmien, toteuttamisen tällä tekniikalla. Nämä järjestelmät käyttivät tyypillisesti päätöspuita ja valikkopohjaisia vuorovaikutuksia vapaamuotoisen keskustelun sijaan, mutta ne edustivat varhaisia yrityksiä automatisoida vuorovaikutusta, joka vaati aiemmin ihmisen puuttumista.
Rajoitukset säilyivät merkittävinä. Nämä järjestelmät olivat hauraita, eivätkä pystyneet käsittelemään odottamattomia syötteitä sulavasti. Ne vaativat tietoinsinööreiltä valtavia ponnisteluja tietojen ja sääntöjen manuaaliseen koodaamiseen. Ja mikä ehkä tärkeintä, he eivät vieläkään kyenneet ymmärtämään luonnollista kieltä sen täydessä monimutkaisuudessa ja moniselitteisyydessä.
Siitä huolimatta tämä aikakausi loi tärkeitä käsitteitä, joista tuli myöhemmin ratkaisevia nykyaikaiselle keskustelun tekoälylle: jäsennelty tiedon esitys, looginen päättely ja toimialueen erikoistuminen. Tilanne oli asetettu paradigman muutokselle, vaikka tekniikka ei ollut vielä aivan valmis.
Asiantuntijajärjestelmät, kuten MYCIN (joka diagnosoi bakteeri-infektiot) ja DENDRAL (joka tunnisti kemiallisia yhdisteitä), järjestivät tietoa jäsenneltyihin tietokantoihin ja käyttivät päätelmäkoneita johtopäätösten tekemiseen. Kun tätä lähestymistapaa sovellettiin keskustelukäyttöliittymiin, chatbotit pystyivät siirtymään yksinkertaisen mallin täsmäyttämisen lisäksi kohti jotain, joka muistuttaa päättelyä – ainakin kapeilla aloilla.
Yritykset aloittivat käytännön sovellusten, kuten automatisoitujen asiakaspalvelujärjestelmien, toteuttamisen tällä tekniikalla. Nämä järjestelmät käyttivät tyypillisesti päätöspuita ja valikkopohjaisia vuorovaikutuksia vapaamuotoisen keskustelun sijaan, mutta ne edustivat varhaisia yrityksiä automatisoida vuorovaikutusta, joka vaati aiemmin ihmisen puuttumista.
Rajoitukset säilyivät merkittävinä. Nämä järjestelmät olivat hauraita, eivätkä pystyneet käsittelemään odottamattomia syötteitä sulavasti. Ne vaativat tietoinsinööreiltä valtavia ponnisteluja tietojen ja sääntöjen manuaaliseen koodaamiseen. Ja mikä ehkä tärkeintä, he eivät vieläkään kyenneet ymmärtämään luonnollista kieltä sen täydessä monimutkaisuudessa ja moniselitteisyydessä.
Siitä huolimatta tämä aikakausi loi tärkeitä käsitteitä, joista tuli myöhemmin ratkaisevia nykyaikaiselle keskustelun tekoälylle: jäsennelty tiedon esitys, looginen päättely ja toimialueen erikoistuminen. Tilanne oli asetettu paradigman muutokselle, vaikka tekniikka ei ollut vielä aivan valmis.
Luonnollisen kielen ymmärtäminen: laskennallisen lingvistiikan läpimurto
1990-luvun lopulla ja 2000-luvun alussa painottui yhä enemmän luonnollisen kielen käsittelyyn (NLP) ja laskennalliseen lingvistiikkaan. Sen sijaan, että yrittäisivät koodata käsin sääntöjä jokaiselle mahdolliselle vuorovaikutukselle, tutkijat alkoivat kehittää tilastollisia menetelmiä auttaakseen tietokoneita ymmärtämään ihmisten kielen luontaisia malleja.
Tämän muutoksen mahdollistivat useat tekijät: lisääntynyt laskentateho, paremmat algoritmit ja mikä tärkeintä, suurten tekstikappaleiden saatavuus, joita voitiin analysoida kielellisten mallien tunnistamiseksi. Järjestelmät alkoivat sisällyttää tekniikoita, kuten:
Puheosan merkintä: sen tunnistaminen, toimivatko sanat substantiivina, verbenä, adjektiivina jne.
Nimettyjen entiteettien tunnistus: Erisnimien (ihmiset, organisaatiot, paikat) tunnistaminen ja luokittelu.
Tunneanalyysi: Tekstin tunnesävyn määrittäminen.
Jäsentäminen: Lauserakenteen analysointi sanojen välisten kielioppisuhteiden tunnistamiseksi.
Yksi merkittävä läpimurto tuli IBM:n Watsonista, joka voitti tunnetusti ihmismestarit tietokilpailussa Jeopardy! Vuonna 2011. Vaikka Watson ei ollutkaan pelkästään keskustelujärjestelmä, se osoitti ennennäkemättömiä kykyjä ymmärtää luonnollisen kielen kysymyksiä, etsiä laajoista tietovarastoista ja muotoilla vastauksia – kykyjä, jotka osoittautuvat välttämättömiksi seuraavan sukupolven chatboteille.
Kaupalliset hakemukset seurasivat pian. Applen Siri julkaistiin vuonna 2011, ja se tuo keskustelurajapinnat valtavirran kuluttajille. Vaikka Siri on nykypäivän standardien rajoittama, se edusti merkittävää edistystä tekoälyassistenttien tekemisessä jokapäiväisten käyttäjien saataville. Microsoftin Cortana, Googlen Assistant ja Amazonin Alexa seurasivat, kumpikin vievät eteenpäin kuluttajille suunnatun keskustelun tekoälyn huippua.
Näistä edistysaskeleista huolimatta tämän aikakauden järjestelmät kamppailivat edelleen kontekstin, maalaisjärkeen päättelyn ja todella luonnolliselta kuulostavan vastausten synnyttämisen kanssa. He olivat kehittyneempiä kuin sääntöihin perustuvat esi-isänsä, mutta he pysyivät pohjimmiltaan rajallisina kielen ja maailman ymmärtämisessä.
Tämän muutoksen mahdollistivat useat tekijät: lisääntynyt laskentateho, paremmat algoritmit ja mikä tärkeintä, suurten tekstikappaleiden saatavuus, joita voitiin analysoida kielellisten mallien tunnistamiseksi. Järjestelmät alkoivat sisällyttää tekniikoita, kuten:
Puheosan merkintä: sen tunnistaminen, toimivatko sanat substantiivina, verbenä, adjektiivina jne.
Nimettyjen entiteettien tunnistus: Erisnimien (ihmiset, organisaatiot, paikat) tunnistaminen ja luokittelu.
Tunneanalyysi: Tekstin tunnesävyn määrittäminen.
Jäsentäminen: Lauserakenteen analysointi sanojen välisten kielioppisuhteiden tunnistamiseksi.
Yksi merkittävä läpimurto tuli IBM:n Watsonista, joka voitti tunnetusti ihmismestarit tietokilpailussa Jeopardy! Vuonna 2011. Vaikka Watson ei ollutkaan pelkästään keskustelujärjestelmä, se osoitti ennennäkemättömiä kykyjä ymmärtää luonnollisen kielen kysymyksiä, etsiä laajoista tietovarastoista ja muotoilla vastauksia – kykyjä, jotka osoittautuvat välttämättömiksi seuraavan sukupolven chatboteille.
Kaupalliset hakemukset seurasivat pian. Applen Siri julkaistiin vuonna 2011, ja se tuo keskustelurajapinnat valtavirran kuluttajille. Vaikka Siri on nykypäivän standardien rajoittama, se edusti merkittävää edistystä tekoälyassistenttien tekemisessä jokapäiväisten käyttäjien saataville. Microsoftin Cortana, Googlen Assistant ja Amazonin Alexa seurasivat, kumpikin vievät eteenpäin kuluttajille suunnatun keskustelun tekoälyn huippua.
Näistä edistysaskeleista huolimatta tämän aikakauden järjestelmät kamppailivat edelleen kontekstin, maalaisjärkeen päättelyn ja todella luonnolliselta kuulostavan vastausten synnyttämisen kanssa. He olivat kehittyneempiä kuin sääntöihin perustuvat esi-isänsä, mutta he pysyivät pohjimmiltaan rajallisina kielen ja maailman ymmärtämisessä.
Koneoppiminen ja tietoihin perustuva lähestymistapa
2010-luvun puoliväli merkitsi uutta paradigman muutosta keskustelun tekoälyssä koneoppimistekniikoiden yleistyessä. Sen sijaan, että luottaisivat käsin laadittuihin sääntöihin tai rajoitettuihin tilastollisiin malleihin, insinöörit alkoivat rakentaa järjestelmiä, jotka pystyivät oppimaan kuvioita suoraan tiedoista – ja suuresta osasta sitä.
Tällä aikakaudella tavoitteellinen luokittelu ja kokonaisuuksien purkaminen nousivat keskusteluarkkitehtuurin ydinkomponentteina. Kun käyttäjä teki pyynnön, järjestelmä:
Luokittele yleinen tarkoitus (esim. lennon varaaminen, sään tarkistaminen, musiikin soittaminen)
Poimi asiaankuuluvat kokonaisuudet (esim. sijainnit, päivämäärät, kappaleiden nimet)
Yhdistä nämä tiettyihin toimiin tai vastauksiin
Facebookin (nyt Metan) Messenger-alustan julkaisu vuonna 2016 antoi kehittäjille mahdollisuuden luoda chatbotteja, jotka voivat tavoittaa miljoonia käyttäjiä, mikä herätti kaupallisen kiinnostuksen aallon. Monet yritykset ryntäsivät ottamaan käyttöön chatbotteja, vaikka tulokset olivat vaihtelevia. Varhaiset kaupalliset toteutukset turhasivat käyttäjiä usein rajallisen ymmärryksen ja jäykkien keskustelujen vuoksi.
Myös keskustelujärjestelmien tekninen arkkitehtuuri kehittyi tänä aikana. Tyypillinen lähestymistapa käsitti erikoiskomponenttien sarjan:
Automaattinen puheentunnistus (ääniliitäntöille)
Luonnollisen kielen ymmärtäminen
Dialogin hallinta
Luonnollisen kielen sukupolvi
Tekstistä puheeksi (ääniliitäntöille)
Jokainen komponentti voidaan optimoida erikseen, mikä mahdollistaa asteittaiset parannukset. Nämä putkiarkkitehtuurit kärsivät kuitenkin joskus virheiden leviämisestä – alkuvaiheessa olevat virheet kaskadivat järjestelmän läpi.
Vaikka koneoppiminen paransi merkittävästi ominaisuuksia, järjestelmät kamppailivat edelleen kontekstin säilyttämisen kanssa pitkien keskustelujen aikana, implisiittisen tiedon ymmärtämisessä ja todella monipuolisten ja luonnollisten reaktioiden luomisessa. Seuraava läpimurto vaatisi radikaalimpaa lähestymistapaa.
Tällä aikakaudella tavoitteellinen luokittelu ja kokonaisuuksien purkaminen nousivat keskusteluarkkitehtuurin ydinkomponentteina. Kun käyttäjä teki pyynnön, järjestelmä:
Luokittele yleinen tarkoitus (esim. lennon varaaminen, sään tarkistaminen, musiikin soittaminen)
Poimi asiaankuuluvat kokonaisuudet (esim. sijainnit, päivämäärät, kappaleiden nimet)
Yhdistä nämä tiettyihin toimiin tai vastauksiin
Facebookin (nyt Metan) Messenger-alustan julkaisu vuonna 2016 antoi kehittäjille mahdollisuuden luoda chatbotteja, jotka voivat tavoittaa miljoonia käyttäjiä, mikä herätti kaupallisen kiinnostuksen aallon. Monet yritykset ryntäsivät ottamaan käyttöön chatbotteja, vaikka tulokset olivat vaihtelevia. Varhaiset kaupalliset toteutukset turhasivat käyttäjiä usein rajallisen ymmärryksen ja jäykkien keskustelujen vuoksi.
Myös keskustelujärjestelmien tekninen arkkitehtuuri kehittyi tänä aikana. Tyypillinen lähestymistapa käsitti erikoiskomponenttien sarjan:
Automaattinen puheentunnistus (ääniliitäntöille)
Luonnollisen kielen ymmärtäminen
Dialogin hallinta
Luonnollisen kielen sukupolvi
Tekstistä puheeksi (ääniliitäntöille)
Jokainen komponentti voidaan optimoida erikseen, mikä mahdollistaa asteittaiset parannukset. Nämä putkiarkkitehtuurit kärsivät kuitenkin joskus virheiden leviämisestä – alkuvaiheessa olevat virheet kaskadivat järjestelmän läpi.
Vaikka koneoppiminen paransi merkittävästi ominaisuuksia, järjestelmät kamppailivat edelleen kontekstin säilyttämisen kanssa pitkien keskustelujen aikana, implisiittisen tiedon ymmärtämisessä ja todella monipuolisten ja luonnollisten reaktioiden luomisessa. Seuraava läpimurto vaatisi radikaalimpaa lähestymistapaa.
Transformer Revolution: hermokielimallit
Vuosi 2017 merkitsi tekoälyn historiassa vedenjakajaa, kun julkaistiin "Attention Is All You Need", joka esitteli Transformer-arkkitehtuurin, joka mullistaisi luonnollisen kielen käsittelyn. Toisin kuin aikaisemmissa lähestymistavoissa, joissa tekstiä käsiteltiin peräkkäin, Transformers pystyi tarkastelemaan koko kohtaa samanaikaisesti, mikä antoi heille mahdollisuuden vangita paremmin sanojen välisiä suhteita riippumatta niiden etäisyydestä toisistaan.
Tämä innovaatio mahdollisti yhä tehokkaampien kielimallien kehittämisen. Vuonna 2018 Google esitteli BERT:n (Bidirectional Encoder Representations from Transformers), joka paransi dramaattisesti suorituskykyä eri kielen ymmärtämistehtävissä. Vuonna 2019 OpenAI julkaisi GPT-2:n, joka osoittaa ennennäkemättömän kyvyn luoda johdonmukaista, kontekstuaalista tekstiä.
Dramaattisin harppaus tuli vuonna 2020 GPT-3:lla, joka skaalautui 175 miljardiin parametriin (verrattuna GPT-2:n 1,5 miljardiin). Tämä valtava mittakaavan lisäys yhdistettynä arkkitehtonisiin parannuksiin tuotti laadullisesti erilaisia ominaisuuksia. GPT-3 pystyi luomaan huomattavan ihmisen kaltaista tekstiä, ymmärtämään kontekstin tuhansista sanoista ja jopa suorittamaan tehtäviä, joihin sitä ei ole erityisesti koulutettu.
Keskustelevassa tekoälyssä nämä edistysaskeleet käännettiin chatbotteiksi, jotka voisivat:
Ylläpidä johdonmukaisia keskusteluja useilla kierroksilla
Ymmärrä vivahteikkaat kyselyt ilman erityistä koulutusta
Luo monipuolisia, asiayhteyteen sopivia vastauksia
Mukauta niiden sävy ja tyyli vastaamaan käyttäjää
Käsittele epäselvyyksiä ja selvennä tarvittaessa
ChatGPT:n julkaisu vuoden 2022 lopulla toi nämä ominaisuudet valtavirtaan ja houkutteli yli miljoona käyttäjää muutamassa päivässä sen julkaisusta. Yhtäkkiä suurella yleisöllä oli pääsy keskustelevaan tekoälyyn, joka vaikutti laadullisesti erilaiselta kuin mikään aikaisempi – joustavampi, asiantuntevampi ja luonnollisempi vuorovaikutuksessa.
Kaupalliset toteutukset seurasivat nopeasti, kun yritykset sisällyttivät suuria kielimalleja asiakaspalvelualustaan, sisällönluontityökaluihinsa ja tuottavuussovelluksiinsa. Nopea käyttöönotto heijasti sekä teknologista harppausta että näiden mallien tarjoamaa intuitiivista käyttöliittymää – keskustelu on loppujen lopuksi ihmisille luonnollisin tapa kommunikoida.
Tämä innovaatio mahdollisti yhä tehokkaampien kielimallien kehittämisen. Vuonna 2018 Google esitteli BERT:n (Bidirectional Encoder Representations from Transformers), joka paransi dramaattisesti suorituskykyä eri kielen ymmärtämistehtävissä. Vuonna 2019 OpenAI julkaisi GPT-2:n, joka osoittaa ennennäkemättömän kyvyn luoda johdonmukaista, kontekstuaalista tekstiä.
Dramaattisin harppaus tuli vuonna 2020 GPT-3:lla, joka skaalautui 175 miljardiin parametriin (verrattuna GPT-2:n 1,5 miljardiin). Tämä valtava mittakaavan lisäys yhdistettynä arkkitehtonisiin parannuksiin tuotti laadullisesti erilaisia ominaisuuksia. GPT-3 pystyi luomaan huomattavan ihmisen kaltaista tekstiä, ymmärtämään kontekstin tuhansista sanoista ja jopa suorittamaan tehtäviä, joihin sitä ei ole erityisesti koulutettu.
Keskustelevassa tekoälyssä nämä edistysaskeleet käännettiin chatbotteiksi, jotka voisivat:
Ylläpidä johdonmukaisia keskusteluja useilla kierroksilla
Ymmärrä vivahteikkaat kyselyt ilman erityistä koulutusta
Luo monipuolisia, asiayhteyteen sopivia vastauksia
Mukauta niiden sävy ja tyyli vastaamaan käyttäjää
Käsittele epäselvyyksiä ja selvennä tarvittaessa
ChatGPT:n julkaisu vuoden 2022 lopulla toi nämä ominaisuudet valtavirtaan ja houkutteli yli miljoona käyttäjää muutamassa päivässä sen julkaisusta. Yhtäkkiä suurella yleisöllä oli pääsy keskustelevaan tekoälyyn, joka vaikutti laadullisesti erilaiselta kuin mikään aikaisempi – joustavampi, asiantuntevampi ja luonnollisempi vuorovaikutuksessa.
Kaupalliset toteutukset seurasivat nopeasti, kun yritykset sisällyttivät suuria kielimalleja asiakaspalvelualustaan, sisällönluontityökaluihinsa ja tuottavuussovelluksiinsa. Nopea käyttöönotto heijasti sekä teknologista harppausta että näiden mallien tarjoamaa intuitiivista käyttöliittymää – keskustelu on loppujen lopuksi ihmisille luonnollisin tapa kommunikoida.
Testaa tekoälyä OMALLA verkkosivullasi 60 sekunnissa
Katso kuinka tekoälymme analysoi verkkosivusi välittömästi ja luo personoidun chatbotin - ilman rekisteröitymistä. Syötä vain URL-osoitteesi ja katso kuinka se toimii!
Valmis 60 sekunnissa
Ei vaadi koodausta
100% turvallinen
Multimodaaliset ominaisuudet: pelkkä tekstikeskustelujen lisäksi
Vaikka teksti on dominoinut keskustelullista tekoälykehitystä, viime vuosina on nähty työntö kohti multimodaalisia järjestelmiä, jotka voivat ymmärtää ja tuottaa monenlaisia mediatyyppejä. Tämä kehitys heijastaa perustavaa laatua olevaa totuutta ihmisten kommunikaatiosta – emme käytä vain sanoja; ele, näytämme kuvia, piirrämme kaavioita ja käytämme ympäristöämme merkityksen välittämiseen.
Visionkieliset mallit, kuten DALL-E, Midjourney ja Stable Diffusion, osoittivat kyvyn luoda kuvia tekstillisistä kuvauksista, kun taas mallit, kuten GPT-4, joissa oli näkökyky, pystyivät analysoimaan kuvia ja keskustelemaan niistä älykkäästi. Tämä avasi uusia mahdollisuuksia keskusteluliittymille:
Asiakaspalvelubotit, jotka voivat analysoida kuvia vaurioituneista tuotteista
Ostosavustaja, joka tunnistaa tuotteet kuvista ja löytää samankaltaisia tuotteita
Koulutustyökalut, jotka voivat selittää kaavioita ja visuaalisia käsitteitä
Esteettömyysominaisuudet, jotka voivat kuvata kuvia näkövammaisille käyttäjille
Myös puheominaisuudet ovat kehittyneet dramaattisesti. Varhaiset puherajapinnat, kuten IVR (Interactive Voice Response) -järjestelmät, olivat tunnetusti turhauttavia, rajoittuen jäykkään komentoihin ja valikkorakenteisiin. Nykyaikaiset puheavustajat voivat ymmärtää luonnollisia puhekuvioita, ottaa huomioon erilaiset aksentit ja puhehäiriöt ja vastata yhä luonnollisemmalta kuulostavalla syntetisoidulla äänellä.
Näiden ominaisuuksien yhdistäminen luo todella multimodaalisen keskustelun tekoälyn, joka voi vaihtaa saumattomasti eri viestintätilojen välillä kontekstin ja käyttäjien tarpeiden mukaan. Käyttäjä voi aloittaa tekstikysymyksellä tulostimen korjaamisesta, lähettää kuvan virheilmoituksesta, saada kaavion, jossa korostetaan asiaankuuluvia painikkeita, ja vaihtaa sitten ääniohjeisiin, kun hänen kätensä ovat kiireisiä korjauksen parissa.
Tämä multimodaalinen lähestymistapa ei edusta vain teknistä edistystä, vaan perustavanlaatuista muutosta kohti luonnollisempaa ihmisen ja tietokoneen vuorovaikutusta – käyttäjien tapaamista missä tahansa viestintätilassa, joka toimii parhaiten heidän nykyisen kontekstin ja tarpeiden mukaan.
Visionkieliset mallit, kuten DALL-E, Midjourney ja Stable Diffusion, osoittivat kyvyn luoda kuvia tekstillisistä kuvauksista, kun taas mallit, kuten GPT-4, joissa oli näkökyky, pystyivät analysoimaan kuvia ja keskustelemaan niistä älykkäästi. Tämä avasi uusia mahdollisuuksia keskusteluliittymille:
Asiakaspalvelubotit, jotka voivat analysoida kuvia vaurioituneista tuotteista
Ostosavustaja, joka tunnistaa tuotteet kuvista ja löytää samankaltaisia tuotteita
Koulutustyökalut, jotka voivat selittää kaavioita ja visuaalisia käsitteitä
Esteettömyysominaisuudet, jotka voivat kuvata kuvia näkövammaisille käyttäjille
Myös puheominaisuudet ovat kehittyneet dramaattisesti. Varhaiset puherajapinnat, kuten IVR (Interactive Voice Response) -järjestelmät, olivat tunnetusti turhauttavia, rajoittuen jäykkään komentoihin ja valikkorakenteisiin. Nykyaikaiset puheavustajat voivat ymmärtää luonnollisia puhekuvioita, ottaa huomioon erilaiset aksentit ja puhehäiriöt ja vastata yhä luonnollisemmalta kuulostavalla syntetisoidulla äänellä.
Näiden ominaisuuksien yhdistäminen luo todella multimodaalisen keskustelun tekoälyn, joka voi vaihtaa saumattomasti eri viestintätilojen välillä kontekstin ja käyttäjien tarpeiden mukaan. Käyttäjä voi aloittaa tekstikysymyksellä tulostimen korjaamisesta, lähettää kuvan virheilmoituksesta, saada kaavion, jossa korostetaan asiaankuuluvia painikkeita, ja vaihtaa sitten ääniohjeisiin, kun hänen kätensä ovat kiireisiä korjauksen parissa.
Tämä multimodaalinen lähestymistapa ei edusta vain teknistä edistystä, vaan perustavanlaatuista muutosta kohti luonnollisempaa ihmisen ja tietokoneen vuorovaikutusta – käyttäjien tapaamista missä tahansa viestintätilassa, joka toimii parhaiten heidän nykyisen kontekstin ja tarpeiden mukaan.
Retrieval-Augmented Generation: Maadoittaa tekoäly tosiasiassa
Vaikuttavista ominaisuuksistaan huolimatta suurilla kielimalleilla on luontaisia rajoituksia. He voivat "halusinoida" tietoa ja ilmoittaa luottavaisesti uskottavalta kuulostavia, mutta vääriä tosiasioita. Heidän tietämyksensä rajoittuu siihen, mikä oli heidän koulutusdatassaan, mikä luo tiedon katkaisupäivämäärän. Ja heillä ei ole kykyä käyttää reaaliaikaisia tietoja tai erikoistuneita tietokantoja, ellei niitä ole erityisesti suunniteltu tekemään niin.
Retrieval-Augmented Generation (RAG) nousi ratkaisuksi näihin haasteisiin. Sen sijaan, että luottaisivat pelkästään koulutuksen aikana opittuihin parametreihin, RAG-järjestelmät yhdistävät kielimallien luovat kyvyt hakumekanismeihin, jotka voivat käyttää ulkoisia tietolähteitä.
Tyypillinen RAG-arkkitehtuuri toimii näin:
Järjestelmä vastaanottaa käyttäjäkyselyn
Se etsii relevanteista tietokannoista kyselyyn liittyvää tietoa
Se syöttää sekä kyselyn että haetut tiedot kielimalliin
Malli tuottaa haettuihin faktoihin perustuvan vastauksen
Tämä lähestymistapa tarjoaa useita etuja:
Tarkempia, tosiasioihin perustuvia vastauksia maadoittamalla luominen varmennettuun tietoon
Mahdollisuus käyttää ajantasaista tietoa mallin harjoittelun rajan yli
Erikoistietoa toimialuekohtaisista lähteistä, kuten yrityksen dokumentaatiosta
Läpinäkyvyys ja nimeäminen mainitsemalla tietolähteet
Keskustelevaa tekoälyä toteuttaville yrityksille RAG on osoittautunut erityisen arvokkaaksi asiakaspalvelusovelluksissa. Esimerkiksi pankkichatbotilla on pääsy uusimpiin käytäntöasiakirjoihin, tilitietoihin ja tapahtumatietueisiin tarjotakseen tarkkoja, henkilökohtaisia vastauksia, jotka olisivat mahdottomia erillisellä kielimallilla.
RAG-järjestelmien kehitys jatkuu haun tarkkuuden parannuksilla, kehittyneemmillä menetelmillä haetun tiedon integroimiseksi generoituun tekstiin ja paremmilla mekanismeilla eri tietolähteiden luotettavuuden arvioimiseksi.
Retrieval-Augmented Generation (RAG) nousi ratkaisuksi näihin haasteisiin. Sen sijaan, että luottaisivat pelkästään koulutuksen aikana opittuihin parametreihin, RAG-järjestelmät yhdistävät kielimallien luovat kyvyt hakumekanismeihin, jotka voivat käyttää ulkoisia tietolähteitä.
Tyypillinen RAG-arkkitehtuuri toimii näin:
Järjestelmä vastaanottaa käyttäjäkyselyn
Se etsii relevanteista tietokannoista kyselyyn liittyvää tietoa
Se syöttää sekä kyselyn että haetut tiedot kielimalliin
Malli tuottaa haettuihin faktoihin perustuvan vastauksen
Tämä lähestymistapa tarjoaa useita etuja:
Tarkempia, tosiasioihin perustuvia vastauksia maadoittamalla luominen varmennettuun tietoon
Mahdollisuus käyttää ajantasaista tietoa mallin harjoittelun rajan yli
Erikoistietoa toimialuekohtaisista lähteistä, kuten yrityksen dokumentaatiosta
Läpinäkyvyys ja nimeäminen mainitsemalla tietolähteet
Keskustelevaa tekoälyä toteuttaville yrityksille RAG on osoittautunut erityisen arvokkaaksi asiakaspalvelusovelluksissa. Esimerkiksi pankkichatbotilla on pääsy uusimpiin käytäntöasiakirjoihin, tilitietoihin ja tapahtumatietueisiin tarjotakseen tarkkoja, henkilökohtaisia vastauksia, jotka olisivat mahdottomia erillisellä kielimallilla.
RAG-järjestelmien kehitys jatkuu haun tarkkuuden parannuksilla, kehittyneemmillä menetelmillä haetun tiedon integroimiseksi generoituun tekstiin ja paremmilla mekanismeilla eri tietolähteiden luotettavuuden arvioimiseksi.
Ihmisen ja tekoälyn yhteistyömalli: oikean tasapainon löytäminen
Kun keskustelun tekoälyominaisuudet ovat laajentuneet, ihmisten ja tekoälyjärjestelmien välinen suhde on kehittynyt. Varhaiset chatbotit asetettiin selkeästi työkaluiksi – rajalliset ja ilmeisesti ei-inhimilliset vuorovaikutuksessaan. Nykyaikaiset järjestelmät hämärtävät nämä rajat ja luovat uusia kysymyksiä tehokkaan ihmisen ja tekoälyn yhteistyön suunnittelusta.
Tämän päivän menestyneimmät toteutukset noudattavat yhteistyömallia, jossa:
Tekoäly käsittelee rutiininomaisia, toistuvia kyselyitä, jotka eivät vaadi ihmisen harkintaa
Ihmiset keskittyvät monimutkaisiin tapauksiin, jotka vaativat empatiaa, eettistä päättelyä tai luovaa ongelmanratkaisua
Järjestelmä tuntee rajoituksensa ja leviää tarvittaessa sujuvasti ihmisagenteille
Siirtyminen tekoälyn ja ihmisen tuen välillä on käyttäjälle saumaton
Ihmisagenteilla on täysi konteksti tekoälyn kanssa käytyjen keskustelujen historiasta
Tekoäly jatkaa oppimista ihmisen toimista ja laajentaa asteittain kykyjään
Tämä lähestymistapa tunnustaa, että keskustelullisen tekoälyn ei pitäisi pyrkiä täysin korvaamaan ihmisten välistä vuorovaikutusta, vaan pikemminkin täydentämään sitä – käsittelemään suuria, yksinkertaisia kyselyitä, jotka kuluttavat ihmisagenttien aikaa ja varmistaen samalla, että monimutkaiset asiat saavuttavat oikean ihmisen asiantuntemuksen.
Tämän mallin toteutus vaihtelee toimialoittain. Terveydenhuollossa tekoäly-chatbotit voivat hoitaa tapaamisaikataulun ja perusoireiden seulonnan varmistaen samalla, että lääketieteelliset neuvot tulevat päteviltä ammattilaisilta. Lakipalveluissa tekoäly voi auttaa asiakirjojen valmistelussa ja tutkimuksessa jättäen tulkinnan ja strategian asianajajien tehtäväksi. Asiakaspalvelussa tekoäly voi ratkaista yleisiä ongelmia ja reitittää monimutkaiset ongelmat erikoistuneille agenteille.
Tekoälyvalmiuksien kehittyessä raja ihmisen osallistumista vaativan ja automatisoitavan välillä muuttuu, mutta perusperiaate säilyy: tehokkaan keskustelevan tekoälyn tulisi parantaa ihmisten kykyjä sen sijaan, että ne vain korvattaisiin.
Tämän päivän menestyneimmät toteutukset noudattavat yhteistyömallia, jossa:
Tekoäly käsittelee rutiininomaisia, toistuvia kyselyitä, jotka eivät vaadi ihmisen harkintaa
Ihmiset keskittyvät monimutkaisiin tapauksiin, jotka vaativat empatiaa, eettistä päättelyä tai luovaa ongelmanratkaisua
Järjestelmä tuntee rajoituksensa ja leviää tarvittaessa sujuvasti ihmisagenteille
Siirtyminen tekoälyn ja ihmisen tuen välillä on käyttäjälle saumaton
Ihmisagenteilla on täysi konteksti tekoälyn kanssa käytyjen keskustelujen historiasta
Tekoäly jatkaa oppimista ihmisen toimista ja laajentaa asteittain kykyjään
Tämä lähestymistapa tunnustaa, että keskustelullisen tekoälyn ei pitäisi pyrkiä täysin korvaamaan ihmisten välistä vuorovaikutusta, vaan pikemminkin täydentämään sitä – käsittelemään suuria, yksinkertaisia kyselyitä, jotka kuluttavat ihmisagenttien aikaa ja varmistaen samalla, että monimutkaiset asiat saavuttavat oikean ihmisen asiantuntemuksen.
Tämän mallin toteutus vaihtelee toimialoittain. Terveydenhuollossa tekoäly-chatbotit voivat hoitaa tapaamisaikataulun ja perusoireiden seulonnan varmistaen samalla, että lääketieteelliset neuvot tulevat päteviltä ammattilaisilta. Lakipalveluissa tekoäly voi auttaa asiakirjojen valmistelussa ja tutkimuksessa jättäen tulkinnan ja strategian asianajajien tehtäväksi. Asiakaspalvelussa tekoäly voi ratkaista yleisiä ongelmia ja reitittää monimutkaiset ongelmat erikoistuneille agenteille.
Tekoälyvalmiuksien kehittyessä raja ihmisen osallistumista vaativan ja automatisoitavan välillä muuttuu, mutta perusperiaate säilyy: tehokkaan keskustelevan tekoälyn tulisi parantaa ihmisten kykyjä sen sijaan, että ne vain korvattaisiin.
Tulevaisuuden maisema: Minne keskustelullinen tekoäly on menossa
Kun katsomme horisonttiin, useat esiin nousevat trendit muokkaavat keskustelullisen tekoälyn tulevaisuutta. Nämä kehityssuunnat eivät lupaa vain asteittaisia parannuksia, vaan potentiaalisia muutoksia vuorovaikutuksessa teknologian kanssa.
Räätälöinti mittakaavassa: Tulevat järjestelmät räätälöivät yhä enemmän vastauksensa välittömän kontekstin lisäksi jokaisen käyttäjän viestintätyyliin, mieltymyksiin, tietotasoon ja suhdehistoriaan. Tämä personointi tekee vuorovaikutuksesta luonnollisempaa ja merkityksellisempää, vaikka se herättääkin tärkeitä kysymyksiä yksityisyydestä ja tietojen käytöstä.
Tunneäly: Vaikka nykyiset järjestelmät pystyvät havaitsemaan perustunnetta, tulevaisuuden keskusteleva tekoäly kehittää kehittyneempää tunneälyä – tunnistaa hienovaraiset tunnetilat, reagoi asianmukaisesti ahdistukseen tai turhautumiseen ja mukauttaa sen sävyä ja lähestymistapaa sen mukaisesti. Tämä ominaisuus on erityisen arvokas asiakaspalvelu-, terveydenhuolto- ja koulutussovelluksissa.
Ennakoiva apu: Selkeiden kyselyjen odottamisen sijaan seuraavan sukupolven keskustelujärjestelmät ennakoivat tarpeet kontekstin, käyttäjähistorian ja ympäristösignaalien perusteella. Järjestelmä saattaa huomata, että suunnittelet useita kokouksia tuntemattomassa kaupungissa, ja tarjota ennakoivasti kuljetusvaihtoehtoja tai sääennusteita.
Saumaton multimodaalinen integraatio: Tulevaisuuden järjestelmät siirtyvät pelkän erilaisten modaliteettien tukemisen lisäksi niiden saumattomasti yhdistämiseen. Keskustelu voi sujua luonnollisesti tekstin, äänen, kuvien ja vuorovaikutteisten elementtien välillä, jolloin kullekin tiedolle voidaan valita oikea modaali ilman käyttäjän nimenomaista valintaa.
Erikoistuneet toimialueen asiantuntijat: Samalla kun yleiskäyttöiset avustajat kehittyvät jatkuvasti, tulemme näkemään myös pitkälle erikoistuneen keskustelun tekoälyn, jolla on syvää asiantuntemusta tietyiltä aloilta – oikeusavustajat, jotka ymmärtävät oikeuskäytännön ja ennakkotapaukset, lääketieteelliset järjestelmät, joilla on kattavat tiedot lääkkeiden yhteisvaikutuksista ja hoitoprotokollista, tai talousneuvojat, jotka ovat perehtyneet verolakeihin ja sijoitusstrategioihin.
Todella jatkuva oppiminen: Tulevat järjestelmät siirtyvät säännöllisen uudelleenkoulutuksen lisäksi jatkuvaan vuorovaikutuksista oppimiseen, ja niistä tulee ajan myötä avuliaampia ja yksilöllisempiä säilyttäen samalla asianmukaiset yksityisyyden suojat.
Näistä jännittävistä mahdollisuuksista huolimatta haasteita on jäljellä. Yksityisyyteen liittyvät huolenaiheet, harhan vähentäminen, asianmukainen läpinäkyvyys ja oikean tason inhimillinen valvonta ovat jatkuvia asioita, jotka muokkaavat sekä teknologiaa että sen sääntelyä. Menestyneimmät toteutukset ovat ne, jotka käsittelevät näitä haasteita harkiten ja tuottavat todellista lisäarvoa käyttäjille.
On selvää, että keskustelullinen tekoäly on siirtynyt markkinarakoteknologiasta valtavirran rajapintaparadigmaan, joka välittää yhä enemmän vuorovaikutustamme digitaalisten järjestelmien kanssa. Evoluutiopolku ELIZAn yksinkertaisesta kuvioiden yhteensovittamisesta nykypäivän hienostuneisiin kielimalleihin edustaa yhtä merkittävimmistä edistysaskeleista ihmisen ja tietokoneen vuorovaikutuksessa – eikä matka ole vielä läheskään ohi.
Räätälöinti mittakaavassa: Tulevat järjestelmät räätälöivät yhä enemmän vastauksensa välittömän kontekstin lisäksi jokaisen käyttäjän viestintätyyliin, mieltymyksiin, tietotasoon ja suhdehistoriaan. Tämä personointi tekee vuorovaikutuksesta luonnollisempaa ja merkityksellisempää, vaikka se herättääkin tärkeitä kysymyksiä yksityisyydestä ja tietojen käytöstä.
Tunneäly: Vaikka nykyiset järjestelmät pystyvät havaitsemaan perustunnetta, tulevaisuuden keskusteleva tekoäly kehittää kehittyneempää tunneälyä – tunnistaa hienovaraiset tunnetilat, reagoi asianmukaisesti ahdistukseen tai turhautumiseen ja mukauttaa sen sävyä ja lähestymistapaa sen mukaisesti. Tämä ominaisuus on erityisen arvokas asiakaspalvelu-, terveydenhuolto- ja koulutussovelluksissa.
Ennakoiva apu: Selkeiden kyselyjen odottamisen sijaan seuraavan sukupolven keskustelujärjestelmät ennakoivat tarpeet kontekstin, käyttäjähistorian ja ympäristösignaalien perusteella. Järjestelmä saattaa huomata, että suunnittelet useita kokouksia tuntemattomassa kaupungissa, ja tarjota ennakoivasti kuljetusvaihtoehtoja tai sääennusteita.
Saumaton multimodaalinen integraatio: Tulevaisuuden järjestelmät siirtyvät pelkän erilaisten modaliteettien tukemisen lisäksi niiden saumattomasti yhdistämiseen. Keskustelu voi sujua luonnollisesti tekstin, äänen, kuvien ja vuorovaikutteisten elementtien välillä, jolloin kullekin tiedolle voidaan valita oikea modaali ilman käyttäjän nimenomaista valintaa.
Erikoistuneet toimialueen asiantuntijat: Samalla kun yleiskäyttöiset avustajat kehittyvät jatkuvasti, tulemme näkemään myös pitkälle erikoistuneen keskustelun tekoälyn, jolla on syvää asiantuntemusta tietyiltä aloilta – oikeusavustajat, jotka ymmärtävät oikeuskäytännön ja ennakkotapaukset, lääketieteelliset järjestelmät, joilla on kattavat tiedot lääkkeiden yhteisvaikutuksista ja hoitoprotokollista, tai talousneuvojat, jotka ovat perehtyneet verolakeihin ja sijoitusstrategioihin.
Todella jatkuva oppiminen: Tulevat järjestelmät siirtyvät säännöllisen uudelleenkoulutuksen lisäksi jatkuvaan vuorovaikutuksista oppimiseen, ja niistä tulee ajan myötä avuliaampia ja yksilöllisempiä säilyttäen samalla asianmukaiset yksityisyyden suojat.
Näistä jännittävistä mahdollisuuksista huolimatta haasteita on jäljellä. Yksityisyyteen liittyvät huolenaiheet, harhan vähentäminen, asianmukainen läpinäkyvyys ja oikean tason inhimillinen valvonta ovat jatkuvia asioita, jotka muokkaavat sekä teknologiaa että sen sääntelyä. Menestyneimmät toteutukset ovat ne, jotka käsittelevät näitä haasteita harkiten ja tuottavat todellista lisäarvoa käyttäjille.
On selvää, että keskustelullinen tekoäly on siirtynyt markkinarakoteknologiasta valtavirran rajapintaparadigmaan, joka välittää yhä enemmän vuorovaikutustamme digitaalisten järjestelmien kanssa. Evoluutiopolku ELIZAn yksinkertaisesta kuvioiden yhteensovittamisesta nykypäivän hienostuneisiin kielimalleihin edustaa yhtä merkittävimmistä edistysaskeleista ihmisen ja tietokoneen vuorovaikutuksessa – eikä matka ole vielä läheskään ohi.